上个月我去顾家家居门店,销售主管老王把手机怼到我脸上,屏幕上是AI自动生成的字幕记录。旁边刚入职的小姑娘脸都绿了——她照着这个错词背了一下午产品卖点。
这画面我记到现在。不是笑,是后怕。咱天天喊AI赋能,结果第一道门槛就卡在词儿上。
今天咱不聊虚的,就把“ai识别词库”这摊子事儿掰开揉碎。我用过腾讯的、阿里的、也试过钉钉那套Fun-ASR,踩坑踩到腿软,总结几条带血的经验。
一、你以为AI是你肚子里的蛔虫?它连你家招牌都念不顺
先说个冷知识:市面上大多数语音识别热词库,单表上限是128个词-2-4。阿里云智能媒体服务宽松点,给到300-8。钉钉那套Fun-ASR因为搞了大模型定制,能塞1000+-5。
但你品,你细品。
我家做家装材料的,光乳胶系列就有“比利时进口Pulse脉冲乳胶”、“荷兰Agro纯物理发泡”、“德国BASF亲肤层”。一套沙发讲下来,专有名词十几个。128个?一个季度新品就挤爆了。
更崩溃的是权重逻辑。腾讯文档写得明白,热词权重1-11,数值越大优先级越高,11叫“超级热词”,100叫“热词增强版”(其实是同音替换,开这功能得烧香)-2。可它没告诉你的是——你把“滨海大厦”权重设成11,确实能识别了,但全公司所有人的会议纪要但凡出现“滨海”,AI都给你脑补成“滨海大厦”。
老王他们公司试过,把店长名字全设成超级热词。结果每周例会出现频率最高的词不是“业绩”,是店长花名。整个词库逻辑崩盘。
所以你看,ai识别词库这事儿,表面是技术活,内里是取舍学。你得想清楚:哪些词必须百分百对,哪些词错了也不死人。128个名额,每一票都珍贵。
二、词库不是造出来就完事,喂不进去等于白搭
大部分人的死穴在这儿:花一星期整理出300个行业黑话,兴冲冲上传,系统提示“单表上限128”。好,你开始做断舍离。
删完上传。第二天发现,昨天那个“核保”权重设低了,识别成“和宝”;前天那个“存储桶”忘加了,转出来是“村出桶”-2-4。
更头疼的是多语种混说。广东的老店,店员跟客户讲产品,三句普通话夹两句粤语。你热词库只支持中文普通话和英文-7,方言词一进系统就成乱码。有次识别“发泡工艺”,转出来“发泡公义”,客户以为在谈买卖公平。
后来我学乖了。不再追求“一步到位”,改走“小步快跑,随时添油”。
现在我们的做法是:每周五下午,各门店把本周识别翻车的词截图发群。运营统一汇总,挑出那些“高频且致命”的,下周一首发进库。权重不设死,先给7,观察一周,不行再调。那些低频生僻词,比如某个客户公司名,当场手动改,不进公共词库,免得污染整体字准率-2。
这套流程跑下来,ai识别词库才真正从“死字典”变成“活搭档”。它不是用来装逼的,是用来擦屁股的。
三、你以为你在训练AI,其实AI在训练你
有个现象特有意思。
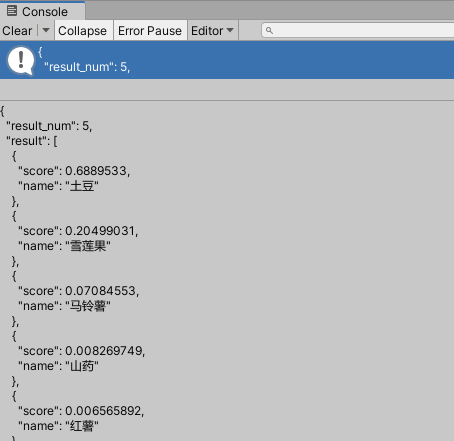
钉钉那篇案例里说,顾家家居定制完专属模型,能准确识别“Sonocore发泡工艺”-5。但你猜这词是怎么被模型记住的?
不是因为你上传了一次词库。是因为你每次开会、每次录播、每次销售话术练习,都在反复念这个词。AI从海量音频里抓到规律:这人一说“搜 no core”,后面必跟“发泡”。它自己学会了。
这叫“上下文感知”-5。比热词权重更高级,也更恐怖。
因为这意味着,你的日常口语习惯,正在反向塑造你公司的数字资产。
我认识一个保险团队,全员东北人,说话自带“咱就说”“那啥”“咋整呢”。结果他们的AI转写系统,现在识别“核保”这种专业词,前面自动补个“那啥”——“那啥核保过了没”。你说它错了?语境全对。你说它对?书面记录没法看。
这不是bug,这是你和AI互相驯化的痕迹。
所以我现在特别警惕一件事:别让ai识别词库变成员工口语的复读机。该规范的话术要规范,该矫正的发音要矫正。技术是为人服务的,不是来迁就你懒的。
四、真正的坑不在识别,在“你以为识别了”
最隐蔽的雷,在翻译场景。
阿里云文档提到一个功能叫“热词转译”-8。啥意思?比如你字幕里出现“智能媒体服务”,它自动给你翻成“IMS”;“永远的神”翻成“The GOAT”-8。
听起来很爽对吧?但你细想:如果这个词库是被多人共用的,A公司设了“智能媒体服务=IMS”,B公司设了“智能媒体服务=Intelligent Media”,你接入同个模板,出来的东西驴唇不对马嘴。
更离谱的是术语库的双向翻译-7。中译英时“P&L”正常该是“盈亏”,结果某人手滑在词库里设了“P&L=API”,从此你所有财报会议字幕,“盈亏”全变“应用程序接口”。
财务总监当场心梗。
这事儿无解,只能认。上个月我把所有关联模板全拆了一遍,一个一个查“直接导入”的Excel文件里有没有乱码符号-2-4。查完发现,去年十月导入的那批热词,有三十多个权重设成100(热词增强版)却完全没人记得开过这功能。等于这一年,系统都在凭“同音替换”瞎猜。
你知道那种感觉吗?你精心喂养的AI,其实一直在吃空气。
五、说了这么多,到底咋整
我没标准答案。各家业务场景差太多,有人需要死磕品牌名,有人只想把售后电话识别准了。但有几个笨办法,兴许能帮你少摔两跤:
第一,热词库不是仓库,是急救箱。别啥破烂都往里塞。通用词比如“客户”“朋友”“公司”,你塞进去只会稀释专有词的命中率-2。省着点用。
第二,权重11是毒药,慎服。设成超级热词确实能保证必认,但副作用是整个系统的容错率下降。除非这个词错一次会死人(比如药品名、飞机部件),否则别轻易上11-2-4。
第三,定期删词比加词更重要。每季度导出一次热词列表,看看哪些词半年没触发过。删掉,给新词腾地儿。128个名额,每一票都要投票给未来,不是给过去。
第四,别迷信大模型定制。钉钉Fun-ASR能听懂家装畜牧十大行业黑话-5,但这背后是上亿小时数据和成百上千家客户喂出来的。你一个中小公司,交完钱能分到多少算力?先问清楚。
结尾
老王后来把那套错漏百出的字幕打印出来,贴在培训室墙上。新销售入职,第一课不是背产品,是找错别字。
“比利时进口血管乳胶”旁边,他用红笔写了一行字:
机器听不懂人话,咱就多说几遍。说到它听懂为止。
这大概就是咱和ai识别词库最真实的相处方式——你没法一步到位,只能边骂边改,边改边用。用到某天突然发现,那个曾经把“脉冲”识别成“卖葱”的系统,居然在你开口前,先替你报出了客户念不顺口的洋品牌名。
那一刻你会原谅所有Bug。
不是因为它变完美了。是因为它终于开始懂你的行业,懂你的口音,懂你为了让它变好,删掉又重填的那128个词,每一个都不是随便选的。